tg-me.com/machinelearning_interview/1495
Last Update:
Одно из лучших иллюстрированных объяснение внутренностей DeepSeek-R1.
▪ Читать
▪ Попробовать
Наивное квантование всех слоев полностью ломает модель, вызывая бесконечные циклы и тарабарщину на выходе. Их динамические кванты решают эту проблему.
1,58-битный квант помещается в 160 ГБ VRAM (2x H100 80 ГБ) для быстрого вывода со скоростью ~140 токенов/сек.
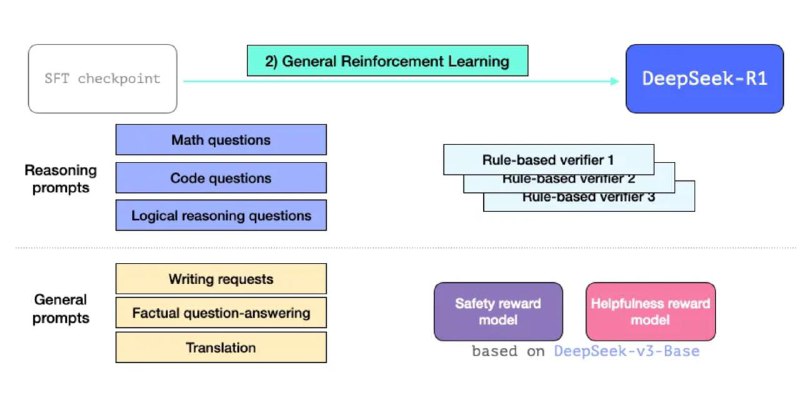
Изучив архитектуру DeepSeek-R1, разработчики выборочно квантовали определенные слои в более высокие биты (например, в 4-битные), а большинство слоев MoE оставили в 1,5 бита.
▪Бенчмарки + блог
▪GGUF (131-212 ГБ) на Hugging Face:
▪Код
▪Демо
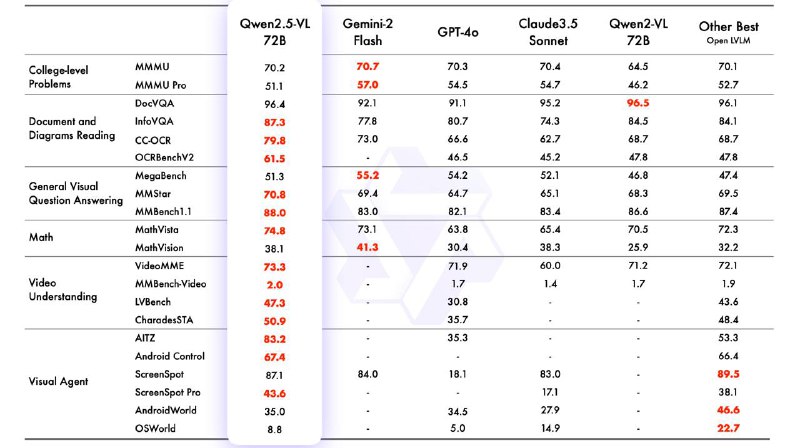
▪Qwen-2.5-VL
▪Qwen-2.5-1M
Netflix выпустили новый алгоритм искажения шума для генерации видео, достаточно быстрый, чтобы работать в реальном времени, который заменяет случайную временную гауссиану на коррелированный искаженный шум, полученный из полей оптического потока, который сохраняет при этом пространственную гауссиану. Эффективность алгоритма позволяет тонко настраивать современные модели диффузии видео с минимальными расходами и предоставляет универсальное решение для широкого спектра управления движением на видео. Обширные эксперименты и исследования демонстрируют преимущества метода, делая его надежным и масштабируемым подходом для управления движением в диффузионных моделях видео.
▪HF
▪Github
▪ Github
@ai_machinelearning_big_data
#ai #ml #news #llm #deepseek #Netflix #Qwen #Pika #news #ainews